When evaluating load balancers, teams often look at features, benchmarks, or latency claims. But the factor that usually determines how far a load balancer can scale is much simpler: where the traffic is processed inside the operating system.
In Linux, packets originate and are handled in the kernel, where the TCP/IP stack runs. User space — where most reverse proxies and L7 load balancers operate — is a separate execution context. When a load balancer is implemented in user space, every packet must travel back and forth between these two layers — which is fundamentally different from kernel-level load balancing, where forwarding happens inside the kernel.
This boundary crossing is subtle, but it has a real cost.
The Cost of Crossing Kernel and User Space
A typical user-space load balancer (like HAProxy in TCP mode, NGINX, Envoy, or Traefik) receives a packet in the kernel, copies it to user space for processing, then returns it to the kernel to send it out. This happens for every packet in the flow.
Each transition triggers:
- a memory copy
- a context switch
- a scheduler hand-off
Individually, these operations are insignificant. Under moderate or heavy load, they accumulate into two visible symptoms:
- Latency grows as concurrency increases
- CPU usage rises faster than throughput
And this is why user-space load balancers often reach a scaling ceiling long before hardware limits are reached. The system is not slow — it is simply doing more work than necessary to move each packet.
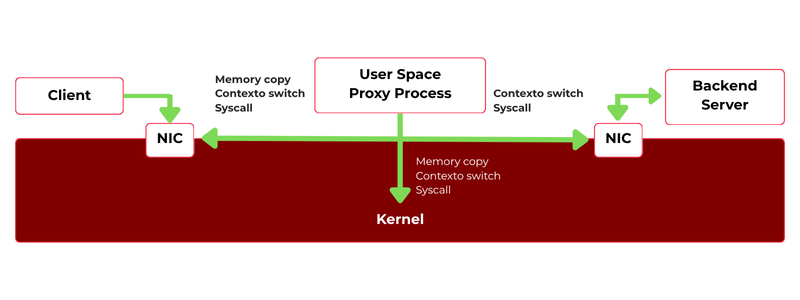
Figure 1. In user-space load balancers, forwarding requires repeated transitions between kernel and user space, increasing latency and CPU overhead.
What Changes When Forwarding Stays in the Kernel
Linux already provides a capable packet-processing engine in the kernel: netfilter for filtering and NAT, and conntrack for connection tracking. If forwarding decisions are made inside the kernel, packets do not need to move up into user space at all — they stay where they originate.
This is the core idea behind kernel-level load balancing. The forwarding path becomes:
Packet arrives → Kernel processes it → Packet leaves
- No additional memory copies.
- No process wake-ups.
- No proxy loop.
This drastically reduces overhead and keeps CPU usage predictable as load increases.
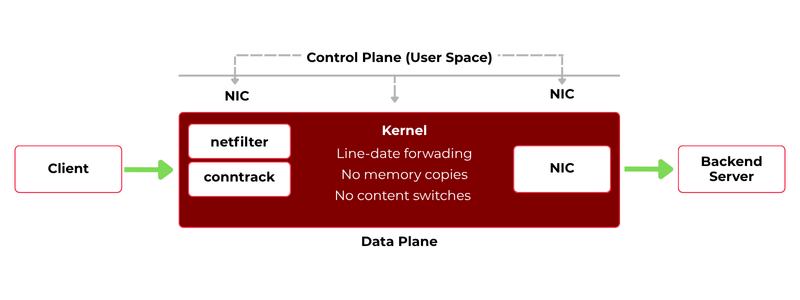
Figure 2. When forwarding occurs in the kernel data plane, packets avoid user-space transitions entirely.
Performance in Real Conditions
This approach is not theoretical. On standard mid-range hardware running SKUDONET L4xNAT, with no DPDK or kernel bypass optimizations:
- 475,983 requests per second
- ~1.63 ms average latency
- ~27% CPU usage
This demonstrates that the improvement does not come from specialized hardware or experimental networking stacks — it comes from where the work is done.
Choosing the Right Forwarding Mode
Kernel-level forwarding supports multiple operational models:
DSR offers the lowest latency, while SNAT provides the most operational control.
The right choice depends on network topology, not performance capabilities.
Keeping Control Without Touching the Data Path
Working directly with netfilter can be complex. Its chains, rule priorities, and packet classification logic require a detailed understanding of kernel-level networking.
SKUDONET addresses this by providing a control plane that defines services, backends, and policies at a higher level, while automatically generating and maintaining the underlying kernel configuration. In this model, the forwarding logic never leaves the kernel, but operators still retain full visibility and control over how traffic is handled.
This is the separation of concerns that makes the architecture both efficient and maintainable:
- Kernel: data path
- User space: control and orchestration
Conclusion
Whether a load balancer processes traffic in user space or in the kernel fundamentally affects:
- Latency stability
- CPU efficieancy
- Scalability under concurrency
- Predictability under load
User-space load balancing offers flexibility and extensibility, but that flexibility comes at the cost of additional data movement and processing overhead. Kernel-level load balancing forwarding avoids this by keeping packet handling in the layer where the traffic already resides, eliminating unnecessary copies and context switches while preserving visibility and control.
If you want to explore the architecture in depth — including packet flow breakdowns, performance measurements, and forwarding mode selection — you can read the full technical paper below.
Download the full technical whitepaper here: